
Seit einigen Jahren, insbesondere seit der Popularisierung von ChatGPT, hören wir immer öfter von künstlicher Intelligenz , die auch für das Vermögensmanagement zu einem wichtigen Investitionsthema geworden ist.
Wir glauben, dass es sich um eine Revolution handelt, die wir derzeit zwar nicht als „radikal“ bezeichnen würden, die aber sicher keine vorübergehende Modeerscheinung sein wird. Vor allem im Finanzbereich haben wir festgestellt, dass der Begriff AI den Begriff Machine Learning (ML) vollständig verdrängt hat. ML wurde früher häufig als Instrument zur Entwicklung von Anlagestrategien genannt. Daher erscheint es uns berechtigt, uns zu fragen, was aus dem ML geworden ist und vor allem, in welchem Verhältnis es zur AI steht.
Wir werden diese Frage mit einem einfachen historischen Abriss beantworten, den wir hoffentlich interessant finden und der sicherlich zur Klärung der Konzepte von AI und ML beiträgt. In diesem Abriss werden wir einige Konzepte darlegen, aber da es sich um ein komplexes Thema handelt, werden wir zwangsläufig allgemein und ungenau sein, um eine Intuition zu vermitteln, ohne den Anspruch auf wissenschaftliche Strenge. ML bedeutet statistisches Lernen durch eine Rechenmaschine (im Wesentlichen einen Computer). Es gibt verschiedene rechnerische Modelle, um dieses Ergebnis zu erzielen: eines davon sind die Artificial Neural Networks (ANN). Der Begriff AI wurde wahrscheinlich geprägt, weil man versuchte, den menschlichen (oder allgemeiner den säugetierartigen) Lernprozess mit einem einfachen mathematisch-statistischen Modell zu formalisieren. Dieser Prozess basiert auf der vereinfachten Nachbildung der Struktur und Funktionsweise des menschlichen Gehirns, das aus Billionen von Neuronen besteht, die elektrische Impulse aussenden, die von Synapsen decodiert werden, die chemische Signale (Neurotransmitter) an die Zielneuronen übertragen. Je nach „Stärke“ der Botschaft kann das Zielneuron ebenfalls aktiviert werden und die Botschaft weiterleiten, wodurch ein Weg innerhalb eines dichten neuronalen Netzwerks aktiviert wird. Synapsen sind für das Lernen verantwortlich, da ähnliche Erfahrungen denselben Neurotransmissionsweg aktivieren.
Eines der ersten Modelle, das versuchte, diese Morphologie und ihre Funktionsweise zu erfassen, war das Perceptron von Rosenblatt (1962) mit einer einzigen Neuronenschicht, zu der durch Netzwerktrainingsverfahren weitere Schichten hinzukamen. Jeder Knoten (der ein physiologisches „Neuron“ stilisiert) im ANN führt eine Berechnung durch und leitet sie an den nächsten Satz von Knoten weiter, gewichtet mit einem Parameter (der die „Synapse“ darstellt). Das Training (oder Lernen) besteht darin, dem Modell Eingabedaten (z. B. Bilder, Texte, Zeitreihen usw.) vorzulegen, um die Modellparameter so zu kalibrieren, dass die Ausgabe den tatsächlich beobachteten Ergebnissen ähnelt (Fehlerminimierung). Nach Abschluss des Lernprozesses ist das ANN in der Lage, zu generalisieren, d. h. auf der Grundlage neuer Eingabedaten mit hoher Wahrscheinlichkeit korrekte Ausgaben zu liefern.
Die am häufigsten verwendete Methode zur Parameterschätzung ist die Backpropagation. Diese zeigte jedoch einen Nachteil: Sie verlieh den Parametern der letzten Knotenschicht ein übermäßiges Gewicht, wodurch die vorherigen Schichten irrelevant wurden. Leider konnten ANN mit nur einer Knotenschicht nur Probleme von begrenzter Komplexität lösen. Aus diesem Grund verloren ANN im Laufe der Zeit an Attraktivität zugunsten anderer ML-Modelle wie der Kernel-Methoden.
In der zweiten Dekade dieses Jahrhunderts jedoch weckten neue ANN-Modelle, insbesondere die Nutzung von Grafikprozessoren (GPU) für parallele Berechnungen und die Verfügbarkeit immer größerer Datenmengen, das Interesse an neuronalen Netzwerken neu: Es entstand das Deep Learning (DL), das zur Lösung sehr komplexer Probleme mit verblüffenden Anwendungen führte, wie z. B. der Fähigkeit, sinnvolle und bedeutungsvolle Texte (Bilder, Töne usw.) zu generieren – das, was als generative künstliche Intelligenz bekannt ist.
Dank der gestiegenen Rechenleistung war es möglich, die Milliarden von Parametern zu schätzen, die für die vielen Schichten künstlicher Neuronen erforderlich sind. Dies erklärt, warum NVIDIA mit seinen neuesten Prozessorgenerationen, wie Hopper zuerst und dann Blackwell, das Wachstum erlebte, das wir heute kennen.
Um eine Vorstellung vom Wachstum der Rechenkapazität zu vermitteln, zeigen wir ein Diagramm, das von der Website von OpenAI heruntergeladen werden kann. Es wird aus optischen Gründen im logarithmischen Maßstab dargestellt, da wir von einem sehr ausgeprägten exponentiellen Wachstum seit 1960 sprechen.
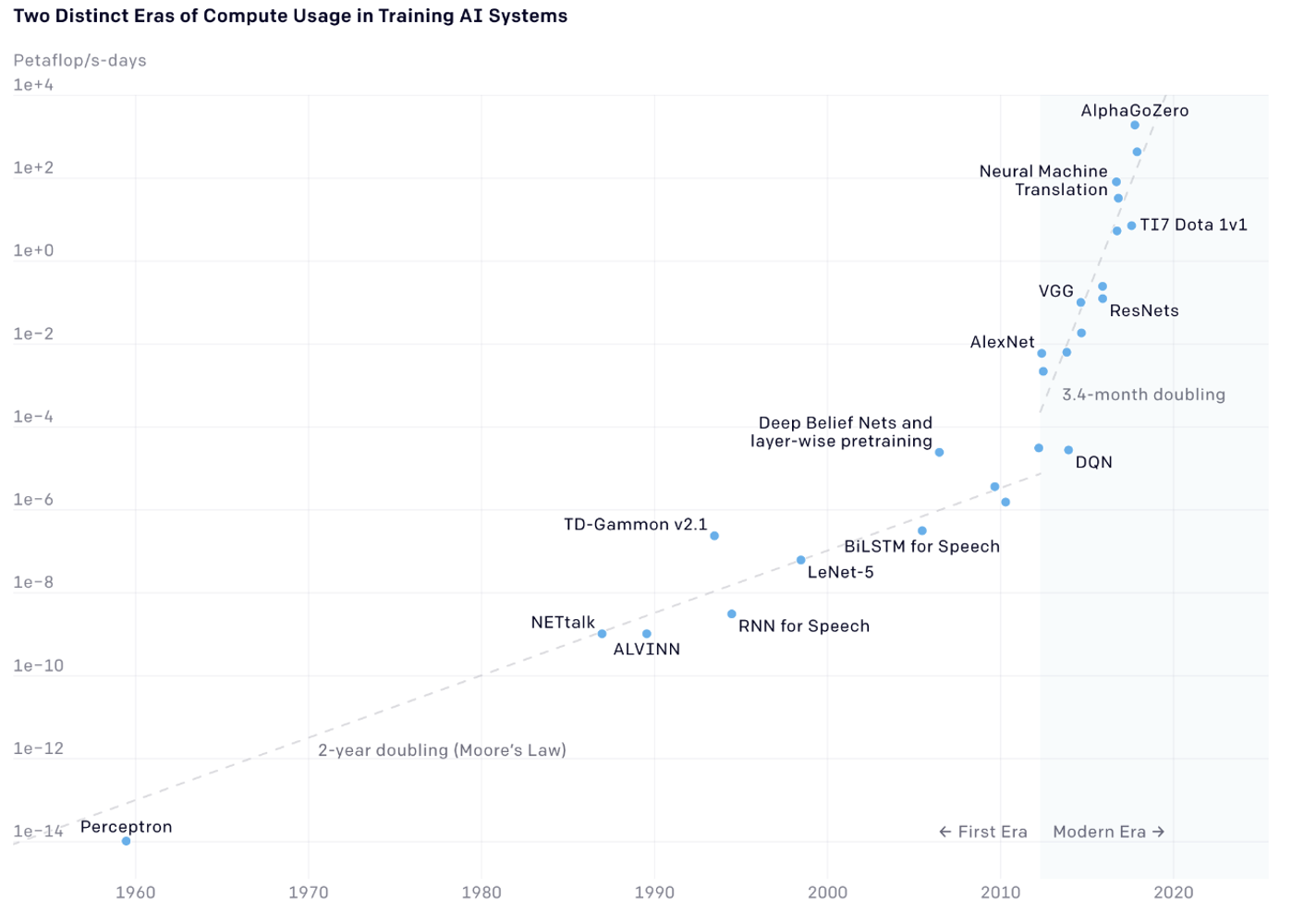
Das Diagramm zeigt den Anstieg der Rechenzyklen der Prozessoren, die von verschiedenen ML-Modellen, die zu ihrer Zeit den Stand der Technik darstellten, benötigt wurden. Das Erstaunliche ist, dass sich während bis 2010 die Taktrate der Prozessoren alle 18 Monate verdoppelte (bekannt als Mooresches Gesetz), sich dieser Zeitraum ab 2010 auf drei bis vier Monate verkürzt hat.
Abschließend kann man AI entweder als einen Zweig des ML betrachten oder die beiden Begriffe synonym verwenden. Wir sind uns bewusst, dass dies eine unkonventionelle Sichtweise ist, da ML häufiger als eine Untergruppe der AI angesehen wird. Wichtig ist jedoch, genau zu wissen, worüber wir sprechen: nämlich über einen neuen wissenschaftlichen und anwendungsbezogenen Ansatz mit einem stark allgegenwärtigen Charakter, der alle Wirtschaftssektoren transversal betrifft und in Zukunft immer mehr betreffen wird – ein unverzichtbares Investmentthema in den kommenden Jahren.
Disclaimer: Dieser Artikel gibt die persönliche Meinung der Mitarbeiter von Custodia Wealth Management wieder, die ihn verfasst haben. Er stellt keine Anlageberatung, keine individuellen Empfehlungen und keine Aufforderung zu Geschäften mit Finanzinstrumenten dar.