
Da qualche anno, in particolare dalla volgarizzazione di ChatGPT, sentiamo parlare di intelligenza artificiale (abbreviata come IA in Italiano o AI in inglese) che è diventato un tema di investimento di primaria importanza anche per la gestione patrimoniale.
Crediamo si tratti di una rivoluzione, che per il momento riteniamo eccessivo classificare come “radicale”, ma che sicuramente non sarà una moda passeggera. Soprattutto in ambito finanziario ci siamo resi conto che il termine AI ha completamente soppiantato il termine Machine Learning (ML) di cui sentivamo spesso parlare anche come strumento per strutturare strategie di investimento. Quindi ci sembra lecito chiederci che fine abbia fatto il ML e soprattutto che rapporto ci sia con AI.
Risponderemo a questa domanda con un semplice excursus storico che speriamo sia d’interesse e che sicuramente contribuisce a chiarire i concetti di AI e ML. In questo excursus esporremo alcuni concetti, ma – trattandosi di una materia complessa – saremo necessariamente generici ed imprecisi badando a trasmettere un’intuizione e senza alcuna pretesa di essere rigorosamente scientifici. ML significa apprendimento su base statistica da parte di una macchina computazionale (un computer, in sostanza).
Esistono vari modelli computazionali per ottenere questo risultato: uno di questi sono le Artificial Neural Network (ANN). Il termine AI è stato coniato probabilmente a causa dei tentativi di formalizzare con un semplice modello matematico/statistico il processo di apprendimento umano (o in generale quello dei mammiferi) basato sulla riproduzione semplificata della struttura e del funzionamento del cervello umano che consta in triliardi di neuroni che comunicano emettendo impulsi elettrici decodificati da sinapsi che trasmettono segnali chimici (neurotrasmettitori) ai neuroni destinatari del “messaggio”. A seconda della “forza” del messaggio il neurone destinatario può a sua volta attivarsi e ritrasmettere il messaggio attivando un percorso all’interno di una fitta rete di neuroni. Le sinapsi sono responsabili dell’apprendimento perché esperienze simili attivano lo stesso percorso di neurotrasmissione.
Uno dei primi modelli che hanno tentato di catturare questa morfologia ed il suo funzionamento fu il perceptron di Rosenblatt (1962) con un solo livello di neuroni a cui si sono aggiunti altri livelli grazie alle tecniche di allenamento della rete. Ogni nodo (che stilizza un “neurone” fisiologico) della ANN esegue un calcolo e lo trasmette al successivo set di nodi ponderato con un parametro (che rappresenta la “sinapsi”). L’allenamento (o apprendimento) consiste nel proporre dati in input (come immagini, testi, serie storiche, ecc.) per calibrare i parametri del modello onde ottenere output simili a quelli realmente verificatesi (minimizzando l’errore). Terminato l’apprendimento la ANN è in grado di generalizzare, ovvero a fronte di nuovi input produrre output corretti con un’alta probabilità. Il metodo di stima dei parametri più utilizzato è la backpropagation che tuttavia ha evidenziato un difetto: attribuiva un peso preponderante ai parametri dell’ultimo livello di nodi rendendo i precedenti irrilevanti. Purtroppo le ANN con un solo livello di nodi riuscivano a risolvere problemi di limitata complessità. Per questo le ANN hanno perso appeal nel tempo a favore dell’ascesa di altri modelli di ML come i metodi kernel.
Nella seconda decade di questo secolo, tuttavia, nuovi modelli di ANN, ma soprattutto lo sfruttamento dei processori delle schede grafiche (GPU) per il calcolo parallelo e la disponibilità di sempre più grandi quantità di dati, hanno risvegliato l’interesse per le reti neuronali: nasceva il deep learning (DL) che ha portato alla soluzione di problemi molto complessi con applicazioni sbalorditive come la capacità di generare testi (immagini, suoni, ecc.) sensati e significativi, quella che è nota come intelligenza artificiale generativa. È merito dell’accresciuta capacità computazionale se la stima dei miliardi di parametri richiesta da molteplici strati di neuroni artificiali è stata possibile. Questo spiega perché NVIDIA con i processori di ultima generazione come Hopper prima e Blackwell poi ha riscontrato lo sviluppo che conosciamo.
Per dare un’idea della crescita di capacità di calcolo riportiamo un grafico scaricabile dal sito di OpenAI che viene rappresentato – per esigenze visive – in scala logaritmica dato che parliamo di una crescita esponenziale molto pronunciata dal 1960.
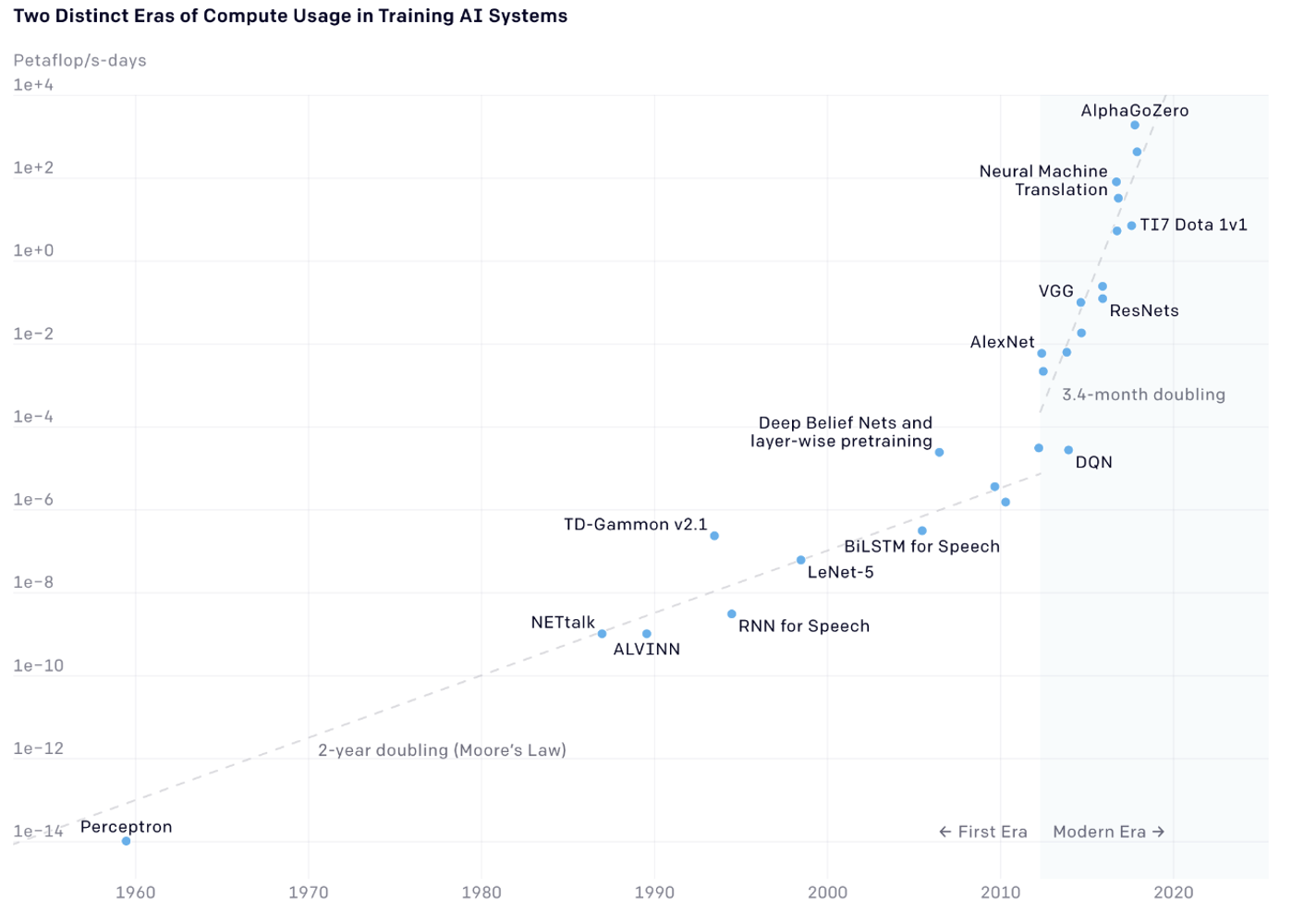
Il grafico mostra l’aumento dei cicli di calcolo dei processori richiesti da vari modelli di ML stato dell’arte in quel momento. L’aspetto strabiliante è che mentre fino al 2010 la frequenza dei clock dei processori raddoppiava ogni 18 mesi (fenomeno noto come legge di Moore), dal 2010 in poi questo periodo si è ridotto a tre/quattro mesi.
In conclusione, si può considerare l’AI come una branca del ML oppure usare i due termini come sinonimi: siamo consapevoli che questo è un punto di vista non standard che invece considera la ML come un sottoinsieme del AI. L’importante è aver ben presente di cosa stiamo parlando, ovvero di un nuovo approccio scientifico ed applicativo dal carattere marcatamente ubiquo che interessa, ed interesserà sempre di più, trasversalmente tutti i settori economici: un tema d’investimento imprescindibile negli anni a venire.
Disclaimer: Il presente articolo esprime l’opinione personale dei collaboratori di Custodia Wealth Management che lo hanno redatto. Non si tratta di consigli o raccomandazioni di investimento, di consulenza personalizzata e non deve essere consideratocome invito a svolgere transazioni su strumenti finanziari.