
Desde hace algunos años, especialmente tras la popularización de ChatGPT, escuchamos hablar de inteligencia artificial (abreviada como IA en italiano o AI en inglés), convertida en un tema clave de inversión también en la gestión patrimonial.
Consideramos que se trata de una revolución, aunque por ahora no la calificaríamos de “radical”, pero seguramente no será una moda pasajera. Especialmente en el ámbito financiero, hemos observado que el término AI ha desplazado por completo al término Machine Learning (ML), que antes se mencionaba con frecuencia como herramienta para diseñar estrategias de inversión. Por ello, nos parece legítimo preguntarnos qué ha sido del ML y, sobre todo, cuál es su relación con la AI.
Responderemos a esta pregunta con un breve recorrido histórico, que esperamos resulte interesante y contribuya a aclarar los conceptos de AI y ML. En este recorrido presentaremos algunas nociones, pero, dado que es un tema complejo, seremos necesariamente generales e imprecisos, con el objetivo de transmitir una intuición más que una explicación científica rigurosa. El ML se refiere al aprendizaje estadístico realizado por una máquina computacional (un ordenador, en esencia). Existen diversos modelos computacionales para lograrlo: uno de ellos son las Redes Neuronales Artificiales (ANN). El término AI probablemente se acuñó al intentar formalizar el proceso de aprendizaje humano mediante un modelo matemático-estadístico sencillo, basado en la reproducción simplificada de la estructura y el funcionamiento del cerebro humano, compuesto por billones de neuronas que se comunican mediante impulsos eléctricos, decodificados por sinapsis que transmiten señales químicas (neurotransmisores) a las neuronas receptoras del “mensaje”. Según la “intensidad” del mensaje, la neurona receptora puede activarse y retransmitirlo, creando un circuito en la densa red neuronal. Las sinapsis son clave en el aprendizaje, ya que experiencias similares activan el mismo recorrido de neurotransmisión.
Uno de los primeros modelos que intentó capturar esta morfología fue el Perceptrón de Rosenblatt (1962), con una sola capa de neuronas, a la que se añadieron más niveles mediante técnicas de entrenamiento de red. Cada nodo (que representa una “neurona” fisiológica) realiza un cálculo y lo transmite a la siguiente capa, ponderado por un parámetro (que simboliza la “sinapsis”). El entrenamiento consiste en alimentar el modelo con datos de entrada (imágenes, textos, series temporales, etc.) para calibrar sus parámetros y producir salidas cercanas a los resultados reales, minimizando el error. Una vez entrenada, la ANN puede generalizar, es decir, generar respuestas correctas frente a nuevas entradas con alta probabilidad.
El método más común para estimar parámetros es la retropropagación (backpropagation), que, sin embargo, evidenció un defecto: daba un peso excesivo a los parámetros de la última capa, anulando la relevancia de las capas anteriores. Además, las ANN de una sola capa solo resolvían problemas simples, lo que llevó a su declive frente a otros modelos de ML, como los métodos de kernel.
En la segunda década de este siglo, no obstante, nuevos modelos de ANN, el uso de procesadores gráficos (GPU) para cálculos paralelos y la disponibilidad de grandes volúmenes de datos reavivaron el interés en las redes neuronales, dando paso al deep learning (DL), que permitió resolver problemas complejos y lograr aplicaciones impresionantes, como la generación de textos (imágenes, sonidos, etc.) coherentes y significativos, conocida como inteligencia artificial generativa.
El aumento de la capacidad computacional permitió estimar miles de millones de parámetros en múltiples capas neuronales, lo que explica el papel clave de NVIDIA con procesadores de última generación, como Hopper primero y Blackwell después.
Para ilustrar el crecimiento de la capacidad de cálculo, se incluye un gráfico descargable desde el sitio web de OpenAI, representado en escala logarítmica debido al crecimiento exponencial observado desde 1960.
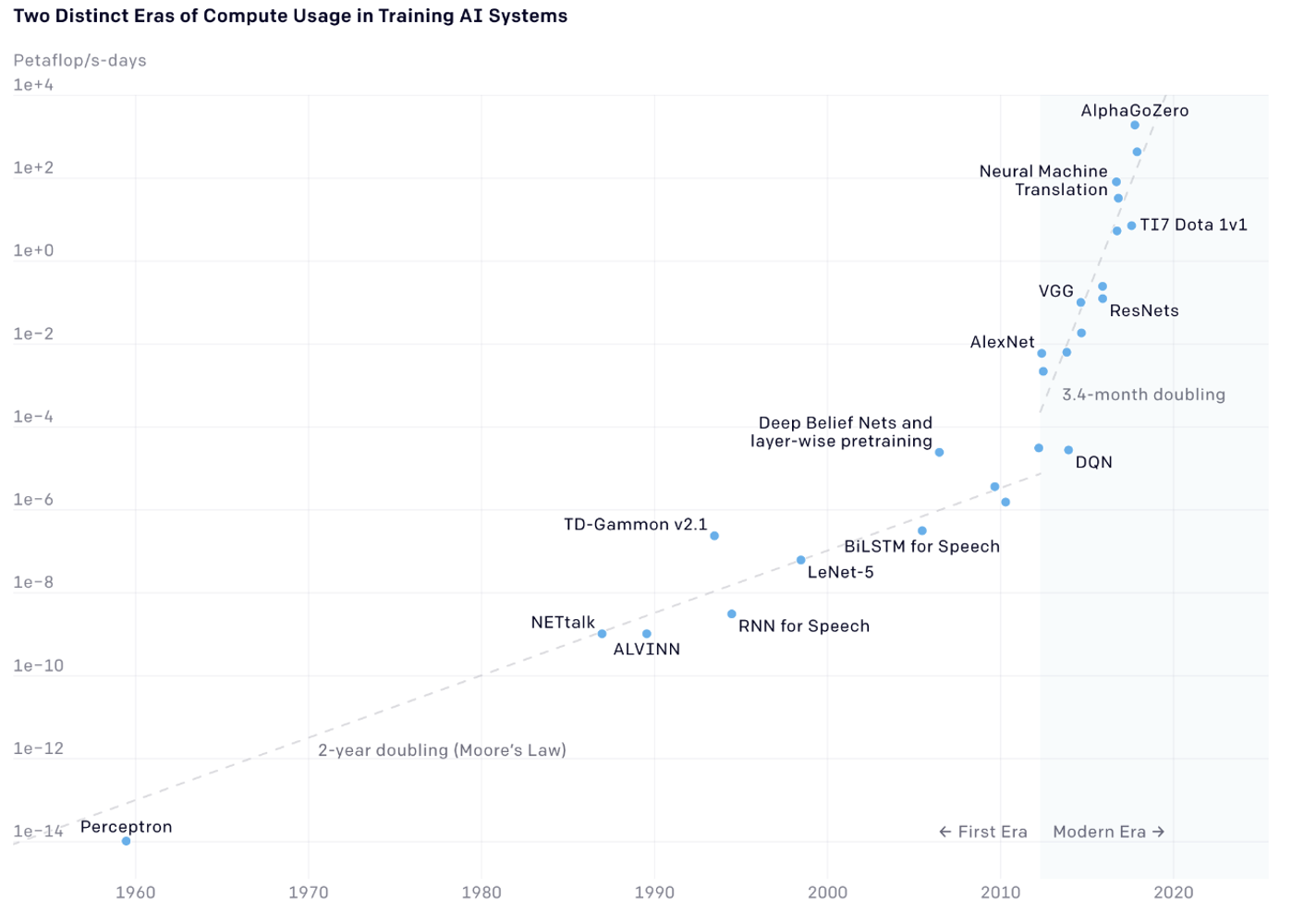
El gráfico muestra el aumento de ciclos de cálculo de los procesadores necesarios para distintos modelos de ML de vanguardia. Sorprende que, mientras hasta 2010 la frecuencia de los procesadores se duplicaba cada 18 meses (ley de Moore), desde entonces este ciclo se ha reducido a tres o cuatro meses.
En conclusión, se puede considerar la AI como una rama del ML o usar ambos términos como sinónimos. Sabemos que esta visión no es la estándar, que suele ver el ML como un subconjunto de la AI. Lo importante es comprender que estamos ante un enfoque científico y práctico de carácter ubicuo, que afecta y afectará cada vez más a todos los sectores económicos, convirtiéndose en un tema de inversión clave para los próximos años.
Disclaimer: Este artículo refleja la opinión personal de los colaboradores de Custodia Wealth Management que lo redactaron. No constituye una recomendación de inversión, asesoramiento personalizado ni invitación a realizar transacciones con instrumentos financieros.