
Há alguns anos, em particular com a popularização do ChatGPT, ouvimos falar sobre inteligência artificial (abreviada como IA em italiano ou AI em inglês), que se tornou um tema de investimento de grande importância também para a gestão patrimonial.
Acreditamos que se trata de uma revolução, que por ora consideramos excessivo classificar como “radical”, mas que certamente não será uma moda passageira. Principalmente no âmbito financeiro, percebemos que o termo AI substituiu completamente o termo Machine Learning (ML), que ouvíamos frequentemente como ferramenta para estruturar estratégias de investimento. Por isso, nos parece legítimo perguntar que fim levou o ML e, sobretudo, qual é a sua relação com a AI.
Responderemos a esta pergunta com um breve percurso histórico, que esperamos ser de interesse e que certamente contribui para esclarecer os conceitos de AI e ML. Neste percurso, apresentaremos alguns conceitos, mas – tratando-se de um tema complexo – seremos necessariamente genéricos e imprecisos, focando em transmitir uma intuição, sem qualquer pretensão de rigor científico.
ML significa aprendizado baseado em estatística por parte de uma máquina computacional (essencialmente, um computador). Existem vários modelos computacionais para alcançar esse resultado: um deles são as Redes Neurais Artificiais (Artificial Neural Networks – ANN).
O termo AI provavelmente surgiu devido às tentativas de formalizar com um simples modelo matemático/estatístico o processo de aprendizado humano (ou, em geral, de mamíferos), baseado na reprodução simplificada da estrutura e do funcionamento do cérebro humano. Este é composto por trilhões de neurônios que comunicam entre si emitindo impulsos elétricos decodificados por sinapses, que transmitem sinais químicos (neurotransmissores) aos neurônios destinatários da “mensagem”. Dependendo da “força” da mensagem, o neurônio destinatário pode, por sua vez, ativar-se e retransmitir a mensagem, criando um percurso dentro de uma densa rede de neurônios. As sinapses são responsáveis pelo aprendizado, pois experiências semelhantes ativam o mesmo percurso de neurotransmissão.
Um dos primeiros modelos que tentou capturar essa morfologia e seu funcionamento foi o Perceptron de Rosenblatt (1962), com uma única camada de neurônios, à qual se acrescentaram outras camadas graças às técnicas de treinamento da rede. Cada nó (que estiliza um “neurônio” fisiológico) da ANN executa um cálculo e o transmite ao conjunto seguinte de nós, ponderado com um parâmetro (que representa a “sinapse”).
O treinamento (ou aprendizado) consiste em propor dados de entrada (como imagens, textos, séries temporais, etc.) para calibrar os parâmetros do modelo, com o objetivo de obter saídas semelhantes às realmente verificadas (minimizando o erro). Concluído o treinamento, a ANN é capaz de generalizar, ou seja, diante de novas entradas, produzir saídas corretas com alta probabilidade.
O método de estimativa de parâmetros mais utilizado é a retropropagação (backpropagation), que, no entanto, revelou um defeito: atribuía um peso excessivo aos parâmetros da última camada de nós, tornando irrelevantes as camadas anteriores. Infelizmente, as ANN com uma única camada de nós só conseguiam resolver problemas de complexidade limitada.
Por isso, as ANN perderam popularidade ao longo do tempo, dando lugar à ascensão de outros modelos de ML, como os métodos de kernel.
Entretanto, na segunda década deste século, novos modelos de ANN – e, sobretudo, a utilização dos processadores de placas gráficas (GPU) para cálculos paralelos, além da disponibilidade crescente de grandes volumes de dados – reacenderam o interesse pelas redes neurais: nasceu o deep learning (DL), que levou à solução de problemas muito complexos com aplicações impressionantes, como a capacidade de gerar textos (imagens, sons, etc.) coerentes e significativos – o que ficou conhecido como inteligência artificial generativa.
Foi graças ao aumento da capacidade computacional que se tornou possível estimar os bilhões de parâmetros necessários para múltiplas camadas de neurônios artificiais.
Isso explica por que a NVIDIA, com processadores de última geração como Hopper e, posteriormente, Blackwell, obteve o desenvolvimento que conhecemos.
Para ilustrar o crescimento da capacidade de processamento, apresentamos um gráfico disponível no site da OpenAI, que é representado – por motivos visuais – em escala logarítmica, dado que se trata de um crescimento exponencial muito acentuado desde 1960.
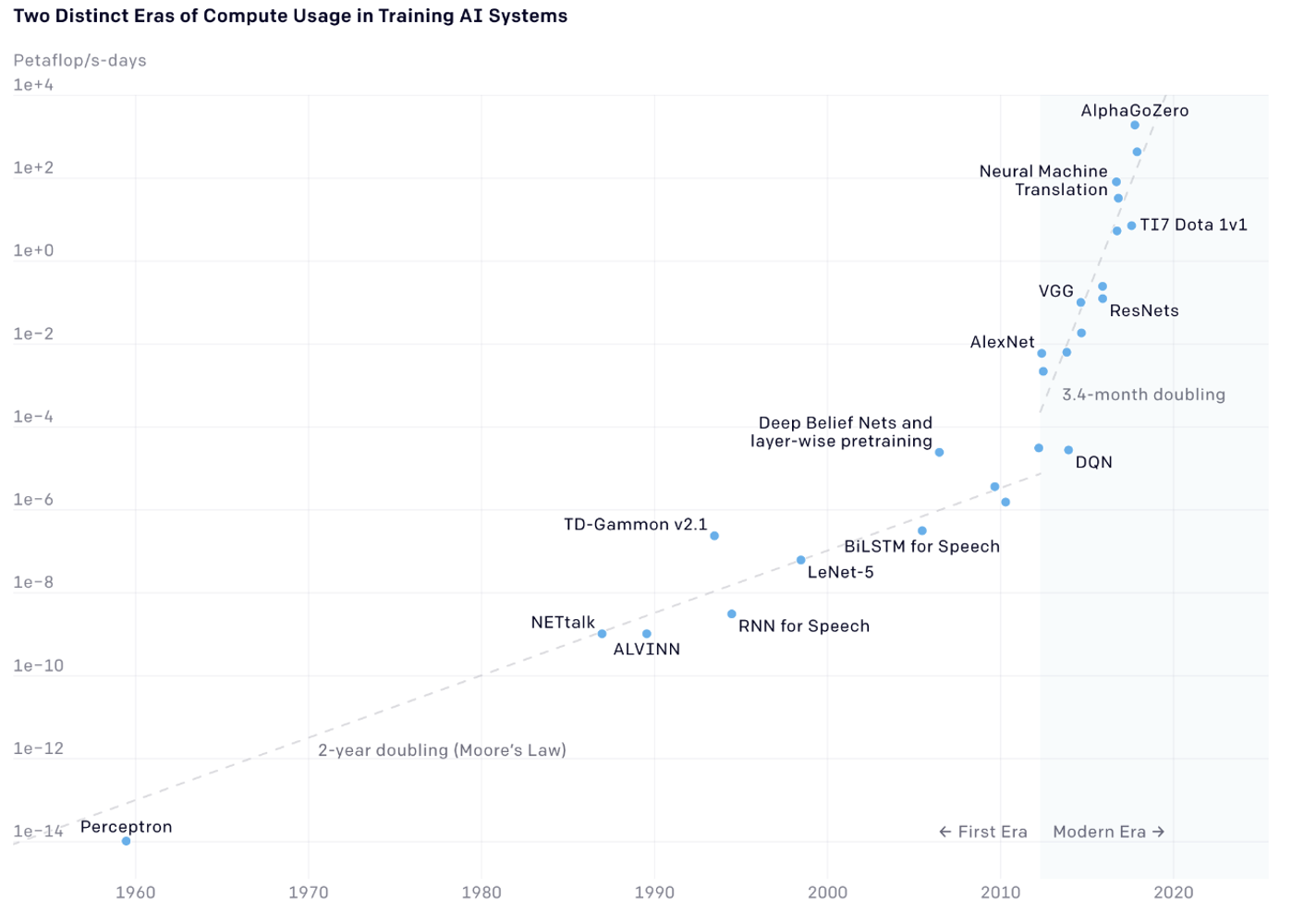
O gráfico mostra o aumento dos ciclos de cálculo dos processadores exigidos por vários modelos de ML estado da arte naquele momento. O aspecto impressionante é que, enquanto até 2010 a frequência dos clocks dos processadores dobrava a cada 18 meses (fenômeno conhecido como lei de Moore), a partir de 2010 esse período foi reduzido para três/quatro meses.
Em conclusão, pode-se considerar a IA como um ramo do ML ou usar os dois termos como sinônimos: estamos cientes de que este é um ponto de vista não padrão, que, ao contrário, considera o ML como um subconjunto da IA. O importante é ter claro sobre o que estamos falando, ou seja, uma nova abordagem científica e aplicada, de caráter marcadamente ubíquo, que interessa, e interessará cada vez mais, transversalmente a todos os setores econômicos: um tema de investimento imprescindível nos anos vindouros.
Disclaimer: Este artigo expressa a opinião pessoal dos colaboradores da Custodia Wealth Management que o redigiram. Não se trata de conselhos ou recomendações de investimento, de consultoria personalizada e não deve ser considerado como convite à realização de transações com instrumentos financeiros.